Why can’t weight preferences be part of the state in multi objective reinforcement learning?
[
A friend and I were looking at the following diagram the other day of a multi-objective Q value network.
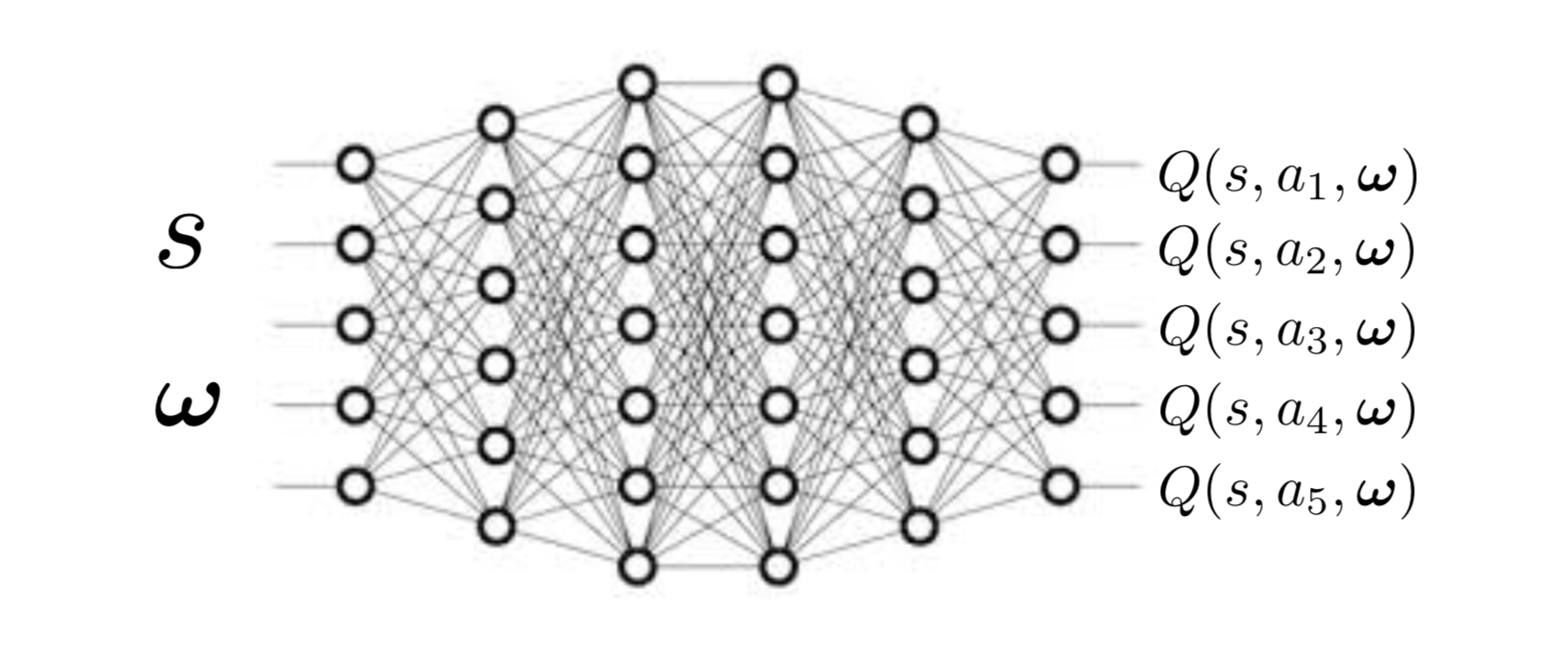
Image Credit: Runzhe Yang
And my friend, asked: “Why can’t the weight preferences be considered
part of the state?” The network takes both state and weights as
input, so why not just consider weighs as part of the state, which
can be formulated however we want?
I had to go back to the formal definition of a Markov Decision Process.
In an MDP is a 4-tuple (S, A, P, R), where P is the probability of the next state given a current state and action.
Weight preferences, however, are not part of this equation. Weight preferences typically come from the a user, and in multi-objective reinforcement learning, the problem setting deals with not knowing a user’s weight preferences beforehand.
More
Archive
chinese tang-dynasty-poetry 李白 python 王维 rl pytorch numpy emacs 杜牧 spinningup networking deep-learning 贺知章 白居易 王昌龄 杜甫 李商隐 tips reinforcement-learning macports jekyll 骆宾王 贾岛 孟浩然 xcode time-series terminal regression rails productivity pandas math macosx lesson-plan helicopters flying fastai conceptual-learning command-line bro 黄巢 韦应物 陈子昂 王翰 王之涣 柳宗元 杜秋娘 李绅 张继 孟郊 刘禹锡 元稹 youtube visdom system sungho stylelint stripe softmax siri sgd scipy scikit-learn scikit safari research qtran qoe qmix pyhton poetry pedagogy papers paper-review optimization openssl openmpi nyc node neural-net multiprocessing mpi morl ml mdp marl mandarin macos machine-learning latex language-learning khan-academy jupyter-notebooks ios-programming intuition homebrew hacking google-cloud github flashcards faker docker dme deepmind dec-pomdp data-wrangling craftsman congestion-control coding books book-review atari anki analogy 3brown1blue 2fa